In two previous blog posts, I explored some natural language techniques using a set of metal lyrics. The first looked at how we could use word frequencies to understand text and the second looked at how we can generate text from a set of examples.
Back in April I had the opportunity to present this work at PyData Amsterdam. You can find a video of my talk here and the slides for it here. It was great fun, and there were lots of interesting talks there. A huge thank you to the PyData committee for organising it.
As part of the preparation for the talk, I tidied up my code for last two blog posts. You can find it on github here. Unfortunately, I'm still not releasing the lyrics themselves. I don't own the copyright for them and am not comfortable releasing them.
I also spend some time exploring another idea:
Quantifying Emotional Arcs
I came across an interesting paper: The emotional arcs of stories are dominated by six basic shapes. The paper explores the idea that most stories follow one of a few "emotional arc" - the large scale changes in emotions felt by the main characters of the story. Apparently this idea goes back to a rejected masters thesis by Kurt Vonnegut. The paper attempts to quantify this idea by applying sentiment analysis to a collection of books from project Gutenburg. The result is "time-series" measuring the average emotion of the story at any point. Decomposing this time series in various was you end up with the set of canonical emotional arcs.
I'm not entirely convinced that the results necessarily prove that there are canonical story arcs (the arcs themselves look a lot like just the lowest Fourier modes of the system...), they do suggest that there is some large scale structure to "emotion" of a story, and that we are able to measure it.
The way in which the "emotion" of the story was measured is also interesting. They used an idea called the Hedonometer - detecting sentiment by assigning a score to common English words. The average score over many words is used as a measure of the "happiness" of a document (original paper here). This method is simple and computationally easy to apply, but seems powerful when averaged over large quantities of text.
The idea of scoring words, and using there average to measure some property of a piece of text got me interested because from my first blog post on metal lyrics, I had a score for the "metalness" of words. I thought it would be fun to use this to look at how "metalness" and "happyness" intersected in word usage.
The Metal/Happy Plane
For the 6000 words which appear in both our score for "Metalness" and the Hedonometer dataset, we have can place the word at a point the in the two-dimensional "Happy/Metal" Plane. A sample of these words are plotted below.
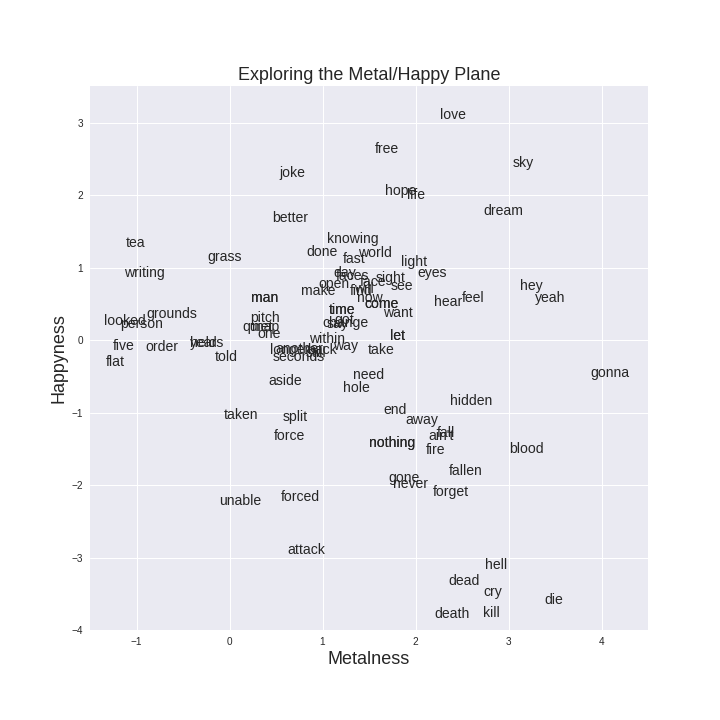
It matches my intuition surprisingly well. Down at the bottom right corner, the metal-unhappy quadrant, we have a cluster of death-related words, ("death", "kill", "die). Slang words like "gonna" and "yeah" end up being metal-neutral due to their disproportionate use in lyrics (compared to the Brown corpus). In the unmetal-happy quadrant at the top left we have words like "tea", "writing" and "grass", and the bottom left corners, the unhappy-unmetal quadrant, things are mostly empty, with the occasional overused violent word appearing ("attack" and "forced").
We can also use this to explore some of the limitations of this approach. In the top right corner, the metal-happy quadrant, we can see words like "dream", "sky" and "love". This position doesn't seem that unreasonable, but words like "love" can mean take on a range of different emotional and metal meaning depending on the context in which it is used, and this context is something our simple word-scorers do not take into account. Consider the following three examples of how the word love is used (selected at random from texts I had open and in memory)
Hate
I'm your hate
I'm your hate when you want love
Pay
Pay the price
Pay, for nothing's fair
They headed down to breakfast, where Mr. Weasley was reading the front page of the Daily Prophet with a furrowed brow and Mrs. Weasley was telling Hermione and Ginny about a love potion she’d made as a young girl. All three of them were rather giggly.
Harry Potter and the Prisoner of Azkaban
She fell in love with his greasy machine
She leaned over wiped his kickstart clean
She'd never seen the beast before
But she left there wanting more more more
Iron Maiden, From here to Eternity
In the first example, love refers to something you can have, in the second it is simply part of the name of a potion, and in the third it is used as some which happened to someone. Each of these is very different, yet in counting words we treat them the same. We make this assumption because taking into account context is very difficult in situations like this. Some approaches that might work are
- to use phrases like "fell in love" in place of just "love"
- to move to a more powerful representation, like in this example from openai, where they used the recurrent output of a RNN trained to predict the next word, with a linear classifier to predict sentiment
- to try and infer the part of speech of each word, and then to apply similar word scoring to the (Word, POS) pairs
Metal Story Arcs
Using the above we can place individual words at a point in a two-dimensional plane. We can extend this to documents by using the average score of each document to define a location. Doing this we can look at Metallica's albums, and explore how they have changed their style over time:
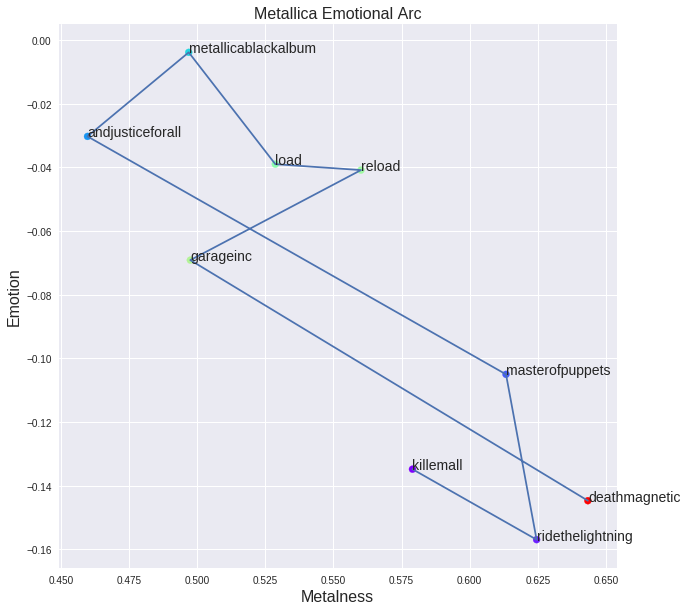
We can see that Metallica's first few albums start deep in the metal, unhappy part of the spectrum, before moving to a happier place. The Black album is almost sentiment-neutral. Since then they've been becoming slowly darker and more metal, moving back to a similar style to their first few albums.
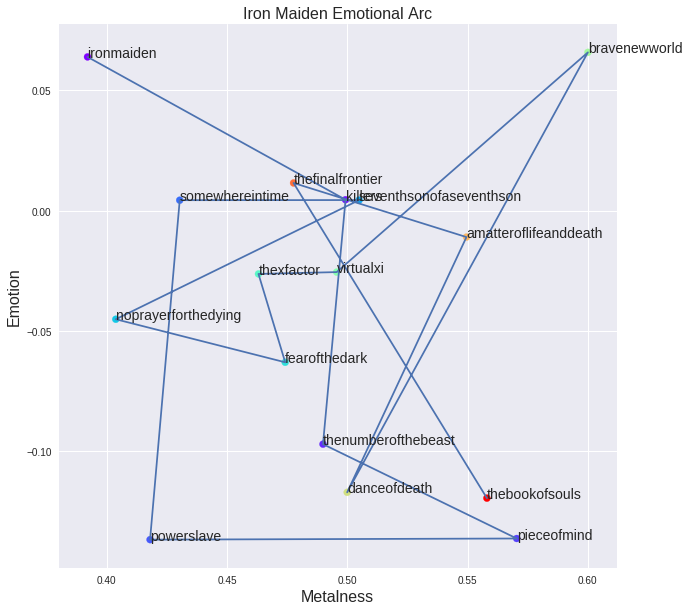
We can do the same for Iron Maiden:
Of course, there is nothing limiting us to applying this technique to Metal lyrics. We can just as easily explore the motion through the Happy/Metal plane of Harry Potter texts:
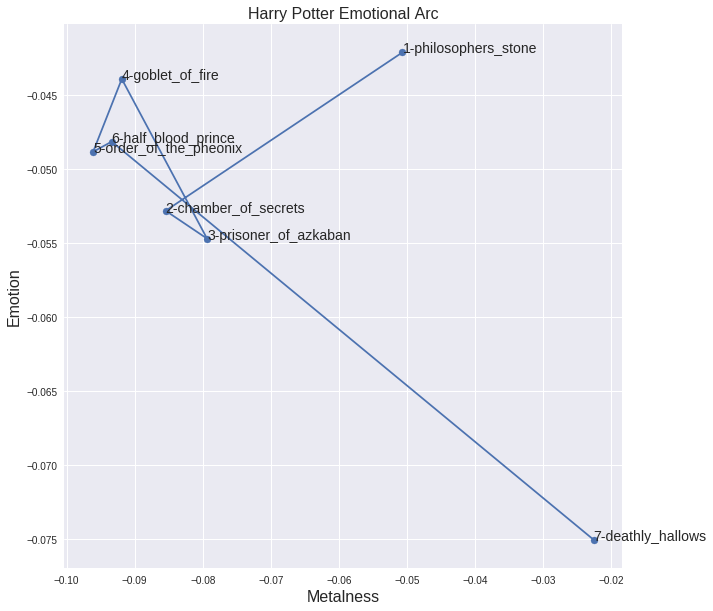
Where, unsurprisingly, Deathly Hallows is the most metal and unhappy of all the Harry Potter series. It is interesting the most of the books are clustered in similar parts of the plane, but the first and the last books are noticeably more metal than the others.
Conclusion
That's all for now. You can find the code used to produce the plots here.
Comments !