Edit: Part 3 of these posts is available here. Most of the code used in these posts is available here.
In a previous post, I explored a corpus of metal lyrics in various ways. Most of these techniques focused on the word frequency within each song, and measures derived from the word frequency.
In this part I am going to look at a different area of natural language processing: Language Generation, or how can we using our existing lyrics to generate lyrics to new songs. This is an very different process from what we looked at before. Simply producing words with a frequency similar to existing songs won't be enough. However, I don't want to "force" the lyrics to take a certain shape, instead I would like the model we use to generate the text to "learn" it from the existing lyrics. Because of this I will be focusing on unsupervised generative models.
Disclaimer 0
My previous post generated more interested then I expected. My motivation for writing it was understanding various natural language processing techniques, and as such it might come across as rather dry and mathematical. This post continues in the same way. My main goal for writing this post is to gain an understanding of language modelling and the theoretical details around it. As such, some might find it unnecessarily technical. If you want to jump straight to generating metal lyrics, head to deepmetal.io.
Disclaimer 1
As in my previous post I refer to lyrics of certain bands as being "Metal". I know some people have strong feelings about how genres are defined, and would probably disagree with me about some of the bands I call metal in this post. I call these band "Metal" here for the sake of brevity only, and I apologise in advance.
Disclaimer 2
I am going to try and generate Metal lyrics. The subject matter of metal lyrics can be Gory, Satanic, Misogynistic and, while I haven't found any examples in my dataset, given the personal views of some artists maybe even racist.
I'm not going to defend the views represented in the lyrics. They don't represent what I believe. But they are what they are, and they are the dataset explored here. As we rely on this data to generate new text, the generated text may offend you. It may or may not be of comfort to know that the algorithm that generates the text has no notion of its semantic meaning - that is provided only by the humans that wrote the original songs.
Language Models
To begin, let's make it clear what we hope to accomplish. We want to "generate" the lyrics to a song randomly. This may seem like a daunting task - writing lyrics for humans is hard. Lyrics have to be coherent (but not too coherent), they have a topic and a structure and maybe event tell a story. They convey emotions and thoughts and ideas. How can we possibly reproduce this with a computer?
The short answer is we can't (currently). Instead we simplify the problem.
When we talk about randomly generating something, we usually start by defining a probability distribution over that thing. Mathematically we could write this as \(P(x_{0}, x_{1}, x_{2}, ... , x_{n})\), where the \(x_{i}\) are the tokens in our sequence (in this case, either words or characters. For now I'm going to keep the distinction ambiguous. Either way we are just generating a sequence of discrete things). This probability distribution is known as a language model - a measure of how likely some sequence is to appear in the domain of interest.
This probability distribution might sound strange. It is a measure of how likely a bunch of words are to be the lyrics a metal song. Depending on how you think about probability, this might not make sense. If it helps, you might like to picture a room of metal lyrics writing monkeys, typing on lyrics on typewriters forever. Each possible sequence of character will appear many times, and what the language model tries to measure is how often each of these appears relative to each other. We would hope that the result is the line "Burn cries eternity" being ranked higher than "particularly indicated secretary".
However you think of them, working with languages models has the advantage that there are well known techniques for building and sampling from them.
Bayesian Beginnings
One difficulty in working with language models is that they describe a sequence, and length of sequences can vary. Some of our first steps in trying to build a language model will be to get around this issue. To begin, we rewrite the distribution using Bayes rule to get
Giving us the probability of the sequence in terms of the probability of the final symbol occurring, given all prior symbols and the probability of all prior symbols occurring. We can repeat this step \(n\) times to get
In this form, the task of building a language model becomes one of building a model for the probability of a symbol appearing, given all the preceding symbols that have appeared. It may not seem like this simplifies the problem as we have replaced a single expression with \(n\) expressions, however, once we make a few approximations things will become clearer.
Markov Approximation
A simple yet powerful approach is known as the Markov Approximation, which assumes that future state of a system depends only on its current state. In the notation of our language model, we can consider the "current state" to be a fixed number of symbols, and the future state to be the next symbol, or:
Where the next symbol depends on the \(k\) previous symbols. In what follows I am going refer to this length-\(k\) sequence as either the current state or context.
The advantage of this approximation is that it removes the dependence of the length of the preceding sequence from \(P\). As we will see later, this will also be a disadvantage.
In this form, the problem of building a language model becomes one of function approximation: we have a fixed input (the \(k\) preceding characters) and a fixed output (the next symbol). We also have example input-output pairs "sampled" from this distribution. Once we have this approximation generation is easy: we start with one state, and then choose the token by sampling from the distribution our function gives us. We then use this to form the next state and repeat until some termination condition.
Maximum Likelihood Models
As function approximations go, creating a simple lookup table is a good first guess: for a given input, we look at all outputs we see in the training data and create a probability distribution from the frequency of each occurrence. Or
Where \(\#(x)\) is a count of how often the symbols \(x\) appear in our training set. This approach is often called a "Markov Chain", but technically this name would apply to any language model that makes the Markov approximation. Instead a better name would be "unsmoothed maximum-likelihood language model. The name comes from the fact that the formula above is the maximum likelihood estimator for \(P(x_{n+1}|x_{n},...,x_{n-k})\), and that no attempt has been made at smoothing (we'll discuss what smoothing is later).
Let's look an example. Consider the first two lines to Iron Maiden's Number of the Beast. Mapping out the connections between words we get:
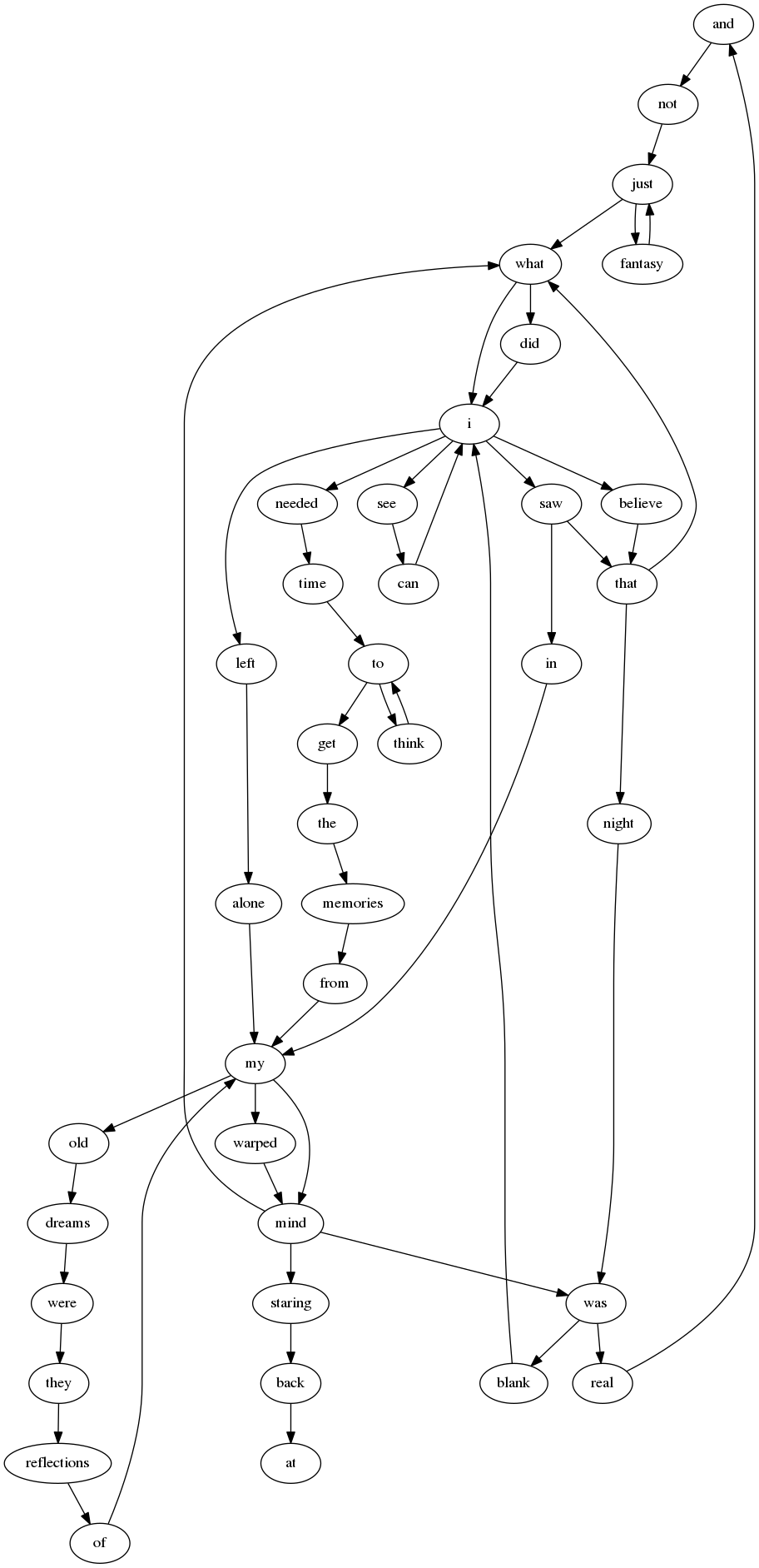
Here each word represents a "state", and the arrows show the words that at some point in the lyrics follow that word. We can use this as a rudimentary language mode that we can generate lyrics from. To do this, we start at one node, and keep following the arrows until we have enough words. Imagine starting at with the word "I", following one path leads to "I left alone, my mind was blank...", the actual first line of the song. We could have followed other paths, generating "I saw that night was blank..." or "I see can I see can I see can" or a number of other possibilities.
Markov Metal Machine
Hopefully this will make more sense if we look at some examples of text generating from this system. I'm going to call it the "Markov Metal Machine". To train it, I am going to use the lyrics from the 119 more popular bands in my dataset (the same as those used in my previous post). This dataset contains 3.5 million words, and 14 million characters.
Before we can train our model, we need to make a decision about what exactly we are going to consider a "state". This is where we have to choose what our "tokens" mean. A sensible choice for this is either a fixed number of characters or a fixed number of words. In advance, it is not obvious what the best choice is, so let's try a few different options and see what comes out. Before that let's step through one example: the two character state.
To start our generation we are going to need an initial state. Imagine we wanted the first line of our song to be "I lived alone, my mind was blank". The last two characters "nk" form the state we use to generate the next characters, giving distribution:
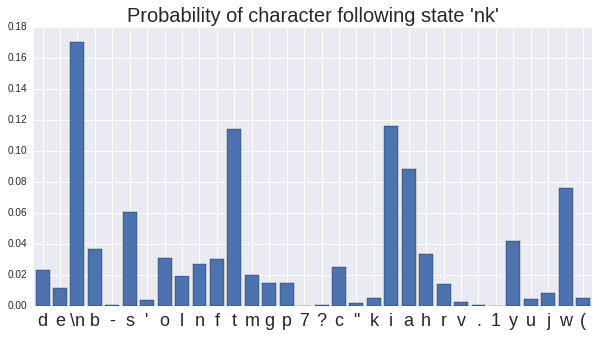
The most likely next character is a new line, as it is in the original Iron Maiden song, but there are a range of options. Remember, to get these probabilities all we did was look through all the lyrics and every time we saw the characters "nk", we counted how many times we saw the next character. Imagine we sampled a character from this distribution, and picked "i". We add this to our generated text to get "I lived alone, my mind was blanki" and set our current state to be "ki", which has the distribution:
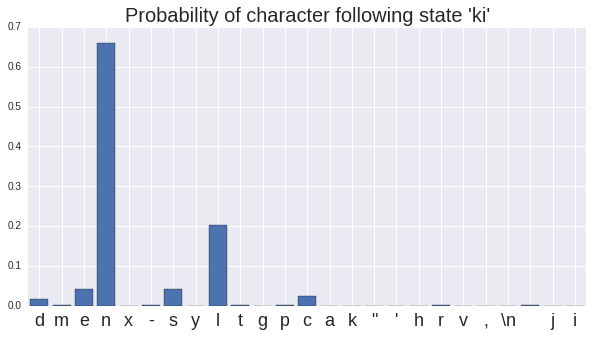
So the most likely next state is "n". We can keep repeating this until we have a complete set of lyrics.
I have done this for a number of different definitions of "state" below:
| State | Generated Text |
|---|---|
| 0 characters | i left alone my mind was blankmati ipmior ar |
| 2 characters | i left alone my mind was blank outris iseed |
| 4 characters | i left alone my mind was blank |
| 8 characters | i left alone my mind was blank |
| 16 characters | i left alone my mind was blank |
| 24 characters | i left alone my mind was blank |
| 0 words | i left alone my mind was blank against patient beaten blood? is |
| 1 words | i left alone my mind was blank into the pressure's getting me something to know i go |
| 2 words | i left alone my mind was blank |
| 4 words | i left alone my mind was blank |
| 7 words | i left alone my mind was blank |
For each different sample, I have seeded the generator again with the same line: "I left alone, my mind was blank". After that, the generator takes there lyrics where ever it wants. The colouring of the words comes from comparing the generated text, to the original song lyrics. From left to right, I find the longest substring that is in the original lyrics, and colour it one colour. The result is that any continuous set text of the same colour comes from the same song.
So what's happening? when the state is zero characters, the Markov Metal Machine (MMM) just generates letters from the frequency with which letters appear in the original text, with no long term dependency at all. The result is a mess once we get to the end of the seed text. By two characters, we don't see words yet, but word-shaped terms. By four characters, most of the words generated are real English words and by eight characters we have full lines that (almost) make sens.
By sixteen characters, the generated text looks like a song. The problem is it only looks like a song because the generated text come from 4 different songs spliced together. The first two lines are the original number of the beast, from there it jumps to Therion – In Remembrance, followed by Motorhead - Time is Right, ending on Deicide - Once apon the Cross. By the time we use 24 characters as our state, there is no variation, the MMM blindly regurgitates "Number of the Beast".
We see similar patterns when using words at states. At 0-words the MMM just generates words randomly. Even though there is no memory at all here, the song looks strangely structured - the generated lyrics are split into lines at roughly the right length. By two words the song almost makes sense. In the short term phrases look like real lyrics, but on the level of lines, the subject matter changes too much and the grammar doesn't make sense. As we will see, this is a common trait of Markov models.
By 4 words, the MMM is again generating multiple lines of actual lyrics, switching from Iron Maiden to Blind Guardian mid-song. By 7 words, things are worse. "Number of the Beast" is almost completely generated, the only break comes from switching to Sabaton - Metal Ripper, a song already made from the lines of other metal songs.
[END]
You might have noticed that several of the songs end with "[END]". This is because of a subtlety I haven't discussed yet: how to terminate the sequence. We can use the function described above to only generate subsequent symbols. Without a way to terminate, this could last forever. One way is to generate only a fixed number of symbols, another is to end each lyric with a termination token. If this is sampled, we end the sequence. I use "[END]" to represent this. I actually use both these mechanisms for samples above. Either the termination character comes up, and I end, or I end if 500 characters are reached.
While the samples above were generated from a seed, we can also include a number of "initial" characters to pad the lyrics at the start, so we also generate the first few tokens as well.
Evaluation
The goal of generating "Metal Lyrics" is a ambiguous one. How would do we know if we've done any good? Following Turing, the best answer I can think of is that if they sound like metal lyrics to a human, then we have probably done a good job. But this sort of evaluation is expensive. I'd love to be able to build thousands of models and have them all ranked by humans, but humans cost money. If we are to generate lyrics algorithmically we would want a way to evaluate the model that generated them algorithmically.
At present I don't know of any automatic measure of "lyric goodness" (If you do, please get in touch). Instead, just as we have generated our lyrics using a "language model" we can evaluate them using ideas from Information Theory. The story goes like this: text is not random. Some strings are more common then others.
Following Shannon's Theorem: if we tried to compress the information in a song lyrics, the minimum space we can compress it to is given by the entropy of our distribution over the lyrics space. While we can't calculate this directly, we can approximate it by trying to use our language model to predict a set of lyrics it hasn't seen before (we call these the validation lyrics). The result is a measure called crossed-entropy. In our case we will be looking at the mean crossed-entropy per token.
If that confuses you, don't worry. The operational meaning of crossed-entropy isn't that important to us. All we need to know is that the better our language model is at predicting the validation lyrics, the lower its crossed-entropy. I use it because it is a common metric used in language modelling (Another closely related metric is perplexity).
Before evaluating our models, I need to bring up a subtlety that will be explored more fully in the next section. Our maximum likelihood models are unsmoothed. This means that if we try to predict the next token in a sequence that our models haven't seen during training it will assign probability zero to it. We need some way around this because if any part of our lyric is judged to have probability zero, the whole sequence will. I use a simple approach: laplace smoothing. Here we replace the probability of the next character with:
Where \(v\) is the number of unknown tokens in our validation set. Much more sophisticated smoothing techniques have been developed but our main goal here is text generation, so I will keep it simple.
Let us start by looking at how mean crossed-entropy varies with the length of our state for the character based models,
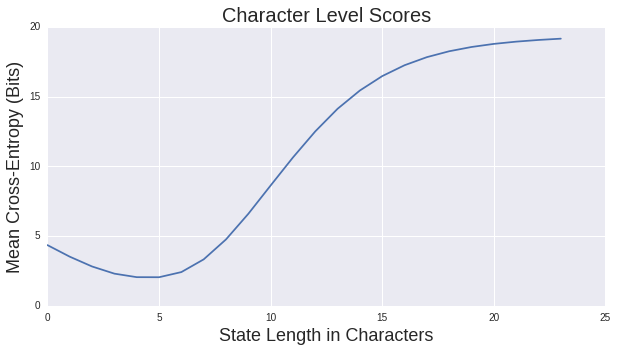
As you can see, it obtains it's best values at 5-character length contexts, with a mean cross-entropy of just over 2-bits per characters. For word level n-grams we get
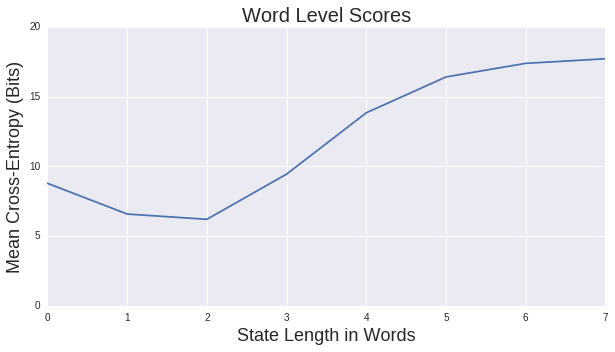
Where we obtain our best results for 2 word contexts, with a with a mean cross-entropy of just over 6-bits per word.
There are two points worth commenting on here:
- While mean cross-entropy is one measure of the quality of a language model, for our purposes it doesn't capture exactly what we are aiming to do: generate lyrics. As such, the best model as chosen by mean cross-entropy is not the one I would have chosen as best representing the balance between novelty and quality of generated lyrics. However, I don't know of a better automated metric.
- For each of these models, once our context state gets too large, our model seems to get worse, much worse then even having no context at all and simply guessing the next word based on overall token frequencies. The reasons for this are discussed in the next section.
The Curse of Dimensionality
The curse of dimensionality is a great name for a band. It is also the reason why as we make the state size of our Markov Metal Machine larger it starts to produce copies of existing song lyrics. In short, the idea says that the number of all possible states grow exponentially with the size of our context, but the number of examples we are using to train our model stays the same size. This means that as the context size grows, only an increasingly tiny faction of states will have been seen before.
The dataset I'm using contains 50 distinct characters: that is 26 characters from the alphabet, 10 digits and 14 punctuation marks. For a state of one character, this means keeping track of just 50 states. For two characters it mean keeping track of \(50^{2} = 2500\), for four characters, 6250000 states. Given our training set contains only have 14 million characters, by the time we hit 8-character states, most contexts wouldn't exist in the model. For our original seed "I lived alone, my mind was blank", the 8 characters context "was blank" has only has one possible next character: a new line.
One way to deal with the curse of dimensionality is to use more data, but often this isn't an option. Another is to find models that allow us to interpolate over values that do not exist in our training data. Whether implicitly or explicitly, this involves making assumptions about how our the underlying data generation process works.
In the following sections, we are going to look at a few techniques that attempt to overcome the curse of dimensinality.
Neural Nets
Neural Nets (NNs) are a method to get around the curse of dimensionality that have become increasingly popular over the last decade. The rough idea is to create a models of recursive logistic regression units, involving millions of parameters trained using stochastic gradient decent to approximate functions. Their success in areas of mapping high dimensional data to low dimensions has been stunning.
While the ideas behind neural networks have around for a few decades, it has been the the last few years that their popularity has exploded due to a few high profile successes. Because of their popularity, a lot has been written about neural nets. I am not an expert, and am not going to try and reproduce the details. Others have done it far more eloquently then I could. For the full mathematical picture of how they work, I highly recommend this book by Micheal Nielsen. For a shorter introduction try here.
From a practical point of view, the following experiments were carried out in Keras and run on an amazon GPU instance. I've been amazed by the power of neural network models. Intuitively, I don't have an explanation of how they are so powerful at learning representations of text. It makes some sense that a model with so many parameters could reproduce the results here. What's impressive is that they can be trained by simple stochastic gradient decent.
Although neural net are powerful, the power comes at a cost. The maximum likelihood models we saw before took twenty minutes to code from scratch. Even using powerful libraries, it took me a while to understand NNs well enough to use. On top of this, training the models here took days of computer time, plus more of my human time tweeking hyper parameters to get the models to converge. I lack the temporal, financial and computational resources to fully explore the hyperparameter space of these models, so the results presented here should be considered suboptimal.
While I am only presenting the working product here, behind them is a story of many failed experiments. Let's see if it was worth it.
Battlemetal Brain
Our first approach with NNs will be to attempt to approximate the function \(P(x_{n+1}|x_{n},...,x_{n-k})\) for various sizes of context. I will be using feed forward networks for this section. For simplicity, I am going to stick to character level models. The best general architecture I found was two feed forward layers of 512 units, followed by a softmax output, with layer normalisation, dropout and tanh activations. Each model was trained for 20 epochs to minimise the mean cross-entropy.
Samples for different context lengths can be found below:
| State | Generated Text |
|---|---|
| 2 characters | i left alone, my mind was blank ing to cand re is we rop rave |
| 4 characters | i left alone, my mind was blank death lines to and i got me the light to fight |
| 10 characters | i left alone, my mind was blankness |
| 20 characters | i left alone, my mind was blanked this the last destruction |
Where the colouring is the same as before.
Plotting the mean crossed entropy against context length
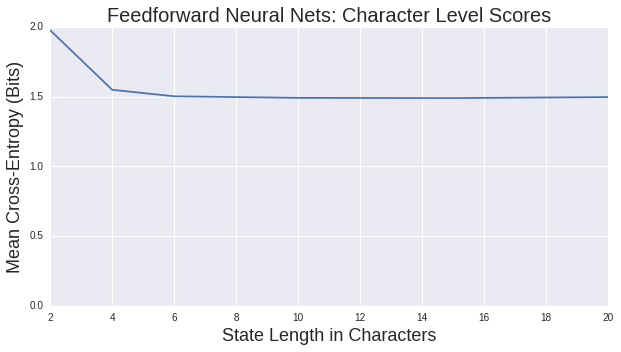
We find that this model quickly beats our maximum likelihood model, then levels off at 1.5 bits per character.
The two character model here looks very much like the one trained in our maximum likelihood model. This is because there isn't much more for our network to learn: when only considering our two character contexts our training data covers most of the options. The four character model gets words just about right, but fails at any longer structure as we'd expect. The longer models are strange. They all have roughly the same MCE score, a lower value then our maximum likelihood model, but don't do as good a job at forming good looking lyrics. The words seem to change half way through.
This model has succeed in not simply regurgitating the training lyrics like our maximum likelihood model, but in doing so we've lost some of the power of the models. I get the feeling this is due to the fact that maximising MCE on existing lyrics fails to capture some part of the text, but I am not yet able to quantify it.
Beyond Markov
So far we have only considered models of the kind \(P(x_{n+1}|x_{n},...,x_{n-k})\), with a fixed notion of the "past". When we look at the outputs of our previous experiments, it sort of looks like there is structure. It's not very good, but we tend not to end up with lines that are too long, and the lines are sometimes arranged into blocks that could be called verses. This is all an accident - none of the models we have looked at so far have any idea what happened more then 25 characters before the current character.
Our main reason for this is generality: we could have imposed some sort of structure from the outside, but it is not obvious how well it would generalise. Not every song obeys a verse-chorus-verse structure, and by creating such a model by hand it feels like we have a system that hasn't learned, but rather blindly copied us (not that this is necessarily a bad thing, it is just not what I am trying to do in this post). In order to do this, we need a way of mapping a variable length input to a fixed length output.
One promising technique for doing this is recurrent neural networks (RNN). The key insight behind RNNs is to take a feedforward neural network and run it across the sequence as you would to predict for a sequence, but to also output a vector. This vector then forms part of the input for the next prediction in the sequence. In this way we are still approximating a fixed length input to fixed length output function, but now the input and output to the function include a vector that gives us some idea of the "history" of the sequence seen so far.
In order to train such a network, you need to be able to "unroll" the network and backpropogate as you would for a feedforward network. This process is called back propagation through time.
Recurrent Rock Radio
The network used here contains two LSTM layers of 512 units each, followed by a fully connected softmax layer. I unroll the sequence for 32 characters and train the model by trying to predict 32 characters, given their immediately preceding characters by minimising the mean cross-entropy.
To train the model, I need to split variable lengthed songs into 32-character chunks. To do this, I ordered songs by length and split them into 128 song long batches. For each 128 song-batch, I padded the the end of the songs to make all the songs within the same batch the same length. I then split each song-batch into 32 character chunks. I then trained the model song-batch by song-batch, resetting the internal state after each song-batch. I call training all of the song-batches once one epoch. The model is trained for 20 epochs.
To generate text from the RNN model, we step character-by-character through a sequence. At each step, we feed the current symbol into the model, and the model returns a probability distribution over the next character. We then sample from this distribution to get the next character in the sequence and this character goes on to become the next input to the model. The first character fed into the model at the beginning of generation is always a special start-of-sequence character.
For this model I only have one variant, so let's look at what the output looks like at different temperatures. The concept of "temperate" refers to how we sample from the output distribution produced by our model. It transforms the distribution by
where \(Z\) is a normalising factor. The higher temperature is, the more random the distribution, the lower the less random. At temperature one we only sample from the original distribution unchanged and at temperature zero we choose only the most likely outcome of the distribution.
The sample look like:
| Temperature | Generated Text |
|---|---|
| Temperature: 2 | i left alone, my mind was blanking...ticfdeemdaks |
| Temperature: 1 | i left alone, my mind was blanken |
| Temperature: 0.5 | i left alone, my mind was blank |
| Temperature: 0.2 | i left alone, my mind was blank |
| Temperature: 0 | i left alone, my mind was blank |
And its score over training epochs:
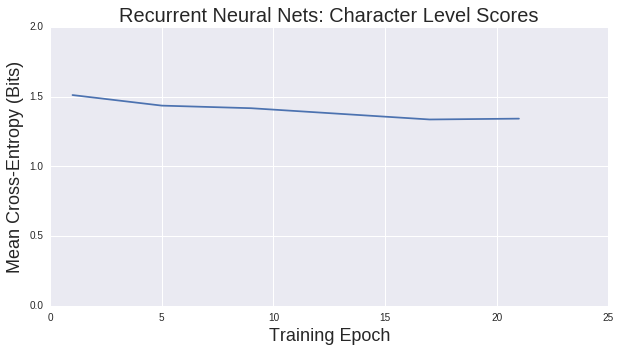
That's pretty amazing. After one training epoch, we've beaten the score of our feed forward networks and our score is still going down, although slowly. We reach a minimum of 1.3 bits per character. The text also feels like it could be real. It still lacks long term coherence, but unlike our previous model it mostly output real words.
As the temperature decreases, the lyrics make less spelling mistakes, but at the cost of become more predictable. By \(T=0\), the model gets stuck in a loop and just repeats "i want to be a single day" over and over again.
Band Style
The models we've looked at some far all try and predict the distribution over the next character in the sequence, given the previous characters. It tries to do this over the distribution of all possible songs, despite the fact that the songs have very different styles and topics. For the feedforward neural network model, this is definitely a problem, and I think the root cause of its switching between words mid-word. In theory the RNN should be able to learn past this given it's ability to store history, but learning long term dependencies is difficult and I'm amazed that it can even learn words from a sequence of characters, let alone styles.
To apply a more direct way to learn styles, I added a second input to my RNN model: an embedding layer that maps from the band to a vector in a two dimensional space. This vector is then concatenated with the other inputs to the model (the current character in the sequence and the history), before being fed into the recurrent layer. The weights of the embedding layer are trainable and the idea is that the network learns the style of the band directly.
Even with this small change the model reach's a score of 1.25 buts per character against our validation set after only 10 epochs. Beyond this it overfits, but the fact that we see a small improvement suggests that there is some small element of style being captured. That said, I am not sure it has captured anything noticeable. Some samples are presented below.
| Band | Generated Text |
|---|---|
| ironmaiden | i left alone, my mind was blank |
| motorhead | i left alone, my mind was blank and i found you to meet your soul |
| machinehead | i left alone, my mind was blank |
| diamondhead | i left alone, my mind was blank |
As the embedding layer maps is two dimensional, we can visualise it. My hope was that the distances between band-embeddings would capture a similarity between their styles, but I'm not convinced that there is anything here.

And with this, I'm done. There are many more models of text generations I'd like to explore, but this post is already too long.
Discussion
By looking at the examples presented here, you would only get a limited feeling for how the models behave. To fully explore it you need to play with the models themselves, which can be found here. If you'd just like to generate some samples, I have put the models online at deepmetal.io to explore.
The lyrics generated here aren't perfect, but they were generated by programs that have no concept or model of what metal lyrics should look like. In all cases, we trained our models by just showing them lots of examples of lyrics and without imposing any requirements of what the output should look like. Given that, I find the results pretty amazing.
These methods aren't the only way to generate lyrics. A promising approach is the one used by Deep Beat, a rap lyrics generator. Rather than generate lyric from scratch, Deep Beat extracts lines from thousands of songs and then given previous lines, tries to find the next best line. By phrasing lyrics generation as an Information retrieval problem, it allows a number of powerful techniques to be used and as the output is a ranked suggestion of the next line, it is far more amenable to human assistance. A downside is that the lines recommended can only come from a fixed set of preexisting lyrics. Combining the approach of Deep Beat with lines generate using techniques presented here could result in a powerful assisted lyric generation tool.
The whole field of computer generated art raises a number of fascinating possibilities. I doubt that any time soon computers will be replacing humans directing in the composition of metal songs, or any other field of artistic endeavour. Instead I think we will see humans using computational tools more and more to augment their natural abilities, and I can't wait to see what we produce.
A Legal Question
While the quality of the lyrics produced here are probably not high enough to be actually used by a band, the idea of computer generated art raises an interesting legal question: who owns it? Some reasonable guesses might be:
- The user who presses "Generate"
- The owner of the computer on which the algorithm is run
- The original bands whose work was used to train the algorithms
- Me
- No one
There seem to be strong argument for each of the above. Some quick research suggest that the matter isn't resolved, mostly due to a lack of cases where this has been a relevant issue (here and here are interesting reads). If anyone with more knowledge then me has a deeper understanding, I'd love to here about it.
In the unlikely case that anyone wants to use the output of the models here commercially, and it turns out that I would be considered the owner, I release any output under the CC0 licence.
Comments !